As I have already covered the creation of a layer stack using the merge function from gdal and I’ve found this great “plugin” OrfeoToolBox (OTB) we can now move one with the classification itself. I’ll show you how to obtain this in QGIS.
Basics
First of all some basics: An unsupervised classification uses object properties to classify the objects automatically without user interference. The user needs to interpret the classes after classification and do some quality checks on the results. The advantages of such an unsupervised approach are:
- fast analysis for first results
- easy to use
- user independent
- repeatable
Yet you need to keep in mind that the computation of those results can take some time. But we will get to this later again.
kmeans
The basic idea behind the kmeans algorithm is that objects close to each other when compared by their attributes are more similar. But what does “close to each other” mean exactly? It states that you need to have the possibility to measure things. So you can compare objects (and a pixel in a raster file is one) by their height, weight, amount of red in their color, consuption of CO2, their possibility to be covered by clouds and of course their spectral reflection in the different bands. Objects with a similar reflection pattern should be similar to each other: We suspect that an apple is similar with a pear as they share color, weight, radius and many other features. So both may belong to the class of fruits.
As we are able to measure the attributes of our objects we are also able to determine the distance between objects looking at the distances of features by using the “euclidean distance in the
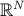 :
:
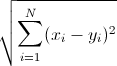
where:
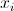 is the measured value of the feature i of object x
is the measured value of the feature i of object x
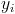 is the measured value of the feature i of object y or in our case the center of a class
is the measured value of the feature i of object y or in our case the center of a class
This will result in a distance matrix which is needed to determine minimal distances between objects x and a given object y.
Additionally kmeans will randomly locate center points for a given number of centers. As you can segmentate the objects now according to their distances to the center we will have an initial classificatioin. Now the algorithm determines the centroid of each segment and use this centroid as the new class center and determines the distances to all obejcts once more. The following animated GIF will give you a little insight:

let’s do this sh*t
Start up QGIS and add your layer stack to the project. We will need this later on to interpret the classes afterwards. Now open up the SEXTANTE toolbox and go the Learning section of the Orfeo Toolbox and double click on Unsupervised KMeans image classification:
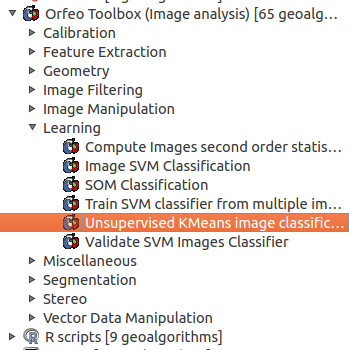
After clicking you will need to make some decissions as this feature will need some input:
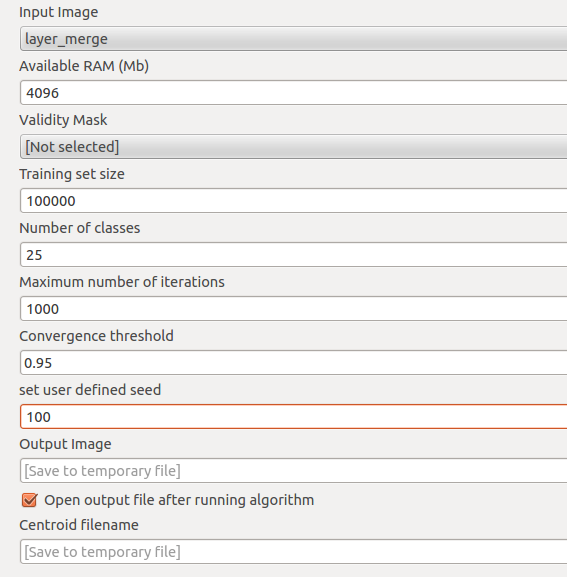
- Input image: your layerstack resulting from the gdal merge function.
- Available RAM: I’ve set this very high as the calculation of distance matrices can address much memory on your machine. especially if you have taking a large sample size and more layers than only 3 or 4 you should be aware of memory consumption.
- Validity mask: I am not using a validity mask as in most cases “0” values will be stored in a separate class which is easy to determin and handled afterwards.
- Training set size: use a large value here as it is better to have a good training sample. Keep in mind that our layer stack has a lot of pixels 😉
- Number of classes: Use as many as possible and as less as needed… Means: take more so you can differentiate objects better. Afterwards you can merge them but you will not be able to split a class afterwards vice versa. The more classes you will take, the more time it will take and the computation will be harder for your pc.
- Maximum number of iterations: Use as much as possible. The training set will be monitored. If more than 1- threshold (see below) is changing the class during one classification step you will do a new iteration. but its better to obtain a certain quality using the threshold instead of having the computation ended without knowning anything about the quality of your classification.
- Convergence threshold: take this as high as possible. 95% is always a good value meaning that 95% of your training set is not changing classes from one iteration to another.
- Set user defined seed: input image will be divided into N lines for better computation(? please comment on this!)
- Ouput Image: I was having the output saved locally and copied it by hand as the immediate saving of the raster by OTB was throwing errors.
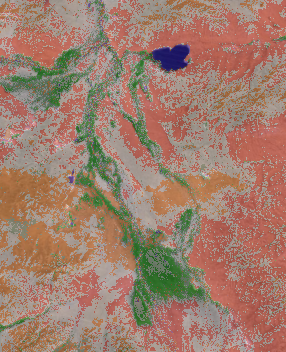
At the end of the process you will probably see a grey image. Open the properties of the image, go to the Style tab and choose pseudocolor:
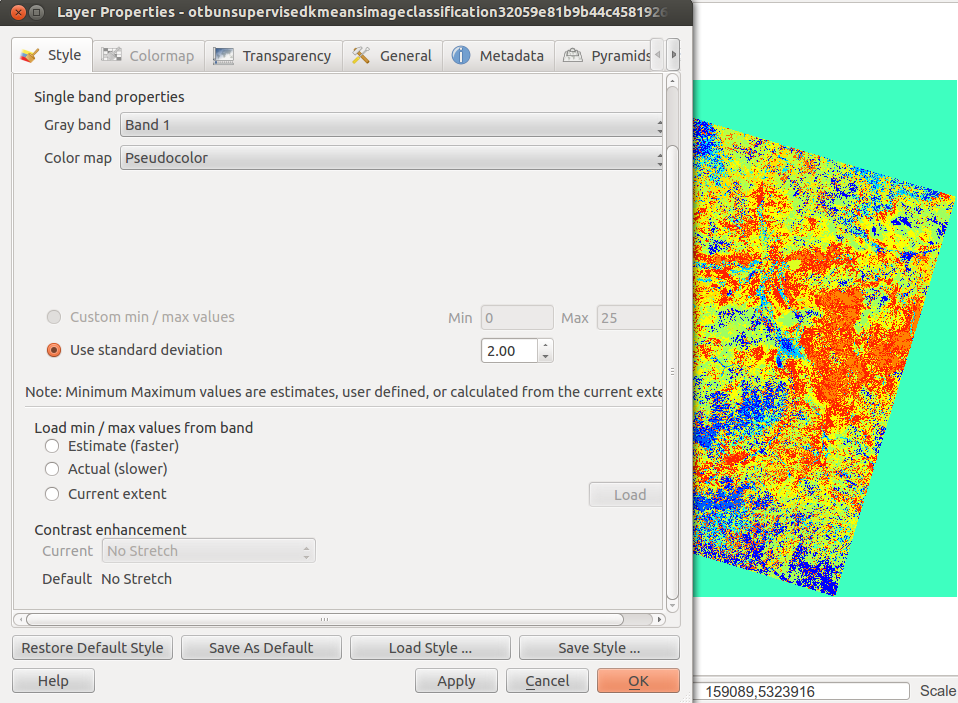
Now you can use the Identify features tool to identify the class of each pixel. Use transparency of the classification layer to see what is beneath compared to the original scene to differentiate each class and choosing a corresponding colour:
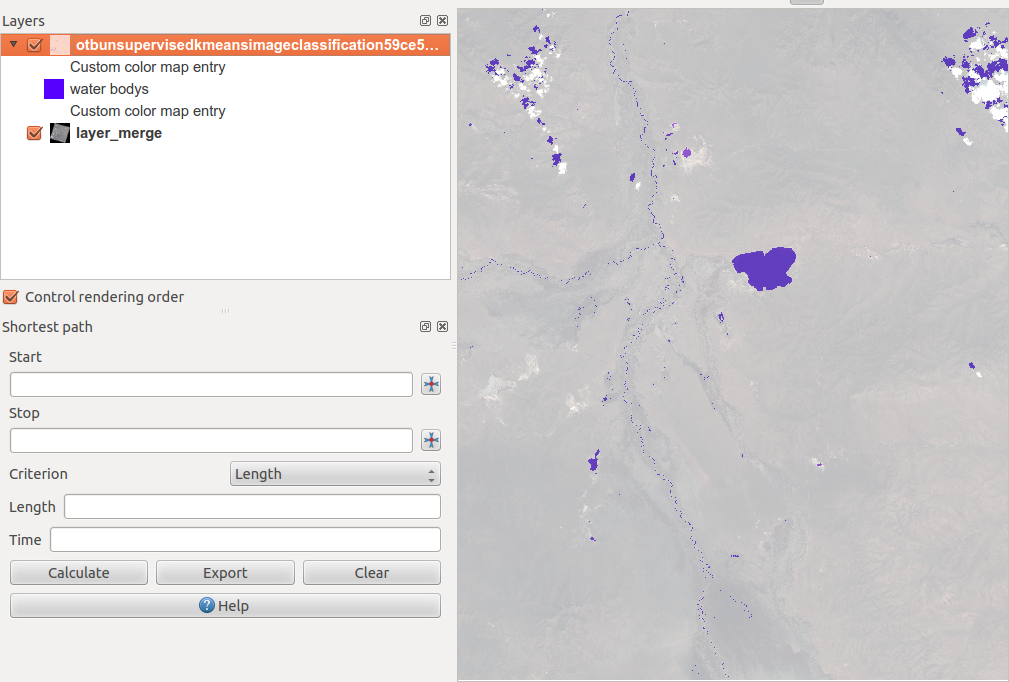
But keep in mind: objects with a comparable spectral signature like shadows and water are also classified as the same. So watch your data carefully and do some analysis on your ROI afterwards!



Great may we need some tutorials to get some hands practicals. Thanks so much. The first law of Geography is applied in many senses.
what do you mean exactly by “Great may we need some tutorials to get some hands practicals” ?
i have an error
Algorithm Unsupervised KMeans image classification starting…
unsupported operand type(s) for +: ‘NoneType’ and ‘str’ See log for more details