In remote sensing you often have to deal with large datsets because their spatial or temporal resolution is high. A typical Landsat 8 scene clocks in at 0.7 – 1 GB and if you are trying to process satellite images for a continent or even the globe you’re easily looking at multiple terrabytes of input data. I am currently working with MODIS time series data, which will use about 4 TB of space even before any processing is done. Therefore I started looking into compression methods. One of the easiest ways to save space is by employing the compression methods some file formats and GDAL drivers support.
As an example we will use the first 7 layers of a Landsat 8 scene from central Germany (LC81940252014200LGN00). If you are working with scientific data lossy compression algorithms are out of the question to compress your input data. GDAL supports three lossless compression algorithms for the GeoTiff format – Packbits, LZW and Deflate. The last two also support predictors to reduce the file size even further.
You can use the compression methods with GDALs creation options.
gdal_translate -of GTiff -co “COMPRESS=LZW” -co “PREDICTOR=2” -co “TILED=YES” uncompressed.tiff LZW-pred2-compressed.tiff
In Python you can use these options as well:
dstImg = driver.Create(dstName, srcImg.RasterXSize, srcImg.RasterYSize, 1, gdal.GDT_Int32, options = [ 'COMPRESS=DEFLATE' ])
Using compression decreases the amount of space you need for your data but it will also increase the amount of time to read and write data. Depending on your situation you’ll have to use the compression method with the ideal trade-off between file size, read and write time. In my case I mostly need a reduction in space. Since I will write once but read often the read times also play an important role.
GDALs standard is to use no predictor for LZW and Deflate compression. Predictors store the difference in neighbouring values instead of the absolute values. If neighbouring pixels corellate this will reduce the file size even further. If not it might even increase it a bit. In other words – if your image contains smooth progression predictors might help, if it contains sudden jumps in values they might not. You can manually set the predictor to 2 for horizontal differencing or 3 for floating point. Since Landsat 8 data has no floating point values (like most satellite imagery) we will only check for horizontal differencing.
Not sure which algorithm will be the best for your data? Neither was I. I therefore wrote a small script that compares all of them to each other in regards to file size, write time and read time. You can then select the best algorithm for your case.
GeoTiff compression benchmark script
Just run it like so and compare the results:
python GTiff_compression_benchmark.py /path/to/some/Geo.tiff
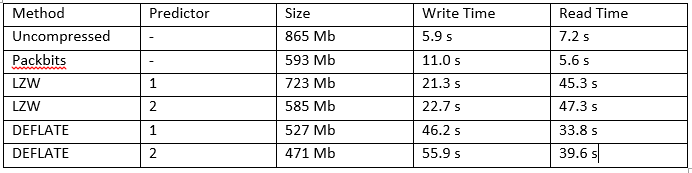
What to take away from that? Packbits is the fastest, but also offers the smallest compressions. Deflate is the smallest, slowest to write but faster to read than LZW. LZW compresses twice as fast as Deflate but is slower to decompress. In my case Deflate with horizontal differencing is the best choice, since it is the smallest and still has OK read times.
— interested in how the code works? keep on reading —
Compression is done with the GDAL command line tools. You first define the command and then execute it with the os.system() function.
command_packbits = "gdal_translate -of GTiff -co \"COMPRESS=PACKBITS\" -co \"TILED=YES\" " + input + " " + packbits os.system(command_packbits)
Reading before processing data is usually done by reading the GeoTiffs into Numpy ndarrays, so that’s what we will do.
def read_tif(img):
return gdal.Open(img).ReadAsArray()
Timing is done with the time module. Define the start time before the command to be executed and substract it from the time after execution.
start_time = time.time() read_packbits = time.time() - start_time
After that it’s just a question of nice printing and making the filesize more human readable, for which we will use hurry.filesize and pandas.DataFrame.
Edit:
After a helpful comment by Markus Neteler I played around with the GDAL_CACHEMAX option. With this you can increase the GDAL block-cache from the standard value to something more fitting of your system. This had no effect on the write times but decreased my read times by ca. 50%.
You can change it permanently following this guideline.


You may consder to add ‘–config GDAL_CACHEMAX 2000’ for an extra speed up. To my knowledge the internal default cache in GDAL is only 40MB, so a larger size is pretty useful…
Great hint! I permanently changed it to a higher value for my architecture following this guideline (http://trac.osgeo.org/gdal/wiki/ConfigOptions). It had no effect on the write times but read times are down by 50%!
Shouldn’t os.system(command_uncompressed) be os.system(command_packbits)?
Indeed it should and it the script it does. I just mixed it up in the example. It should be correct now.
Thanks for the comparison which was quite helpful. But allow me one comment: DEFLATE isn’t lossless. compare: http://blog.cleverelephant.ca/2015/02/geotiff-compression-for-dummies.html or the gdal help.
According to that link, DEFLATE is lossless.
Thanks for the comparison.
I’m new in GDAL, I don’t know why, but probably I’m doing it wrongly …
when I doing
gdal_translate src.vrt out.tif -co compress=lzw
seems no compression given, 1.1 Gigabyte for a 24632x16316pixels input file
(I follow this link:
https://trac.osgeo.org/gdal/wiki/UserDocs/GdalWarp
)
but, when I follow your way using -co
gdal_translate -of GTiff -co “COMPRESS=LZW” -co “PREDICTOR=2” -co “TILED=YES” src.vrt out.tif
the resulted tif image is only 636MB …
[…] https://digital-geography.com/geotiff-compression-comparison/ http://blog.cleverelephant.ca/2015/02/geotiff-compression-for-dummies.html […]
Hello, I understand this post was written a long time ago but I hope you can see my comments and help me with my issue. First, thank you for the nice comparison, I am doing something similar myself but by using rasterio library (built around GDAL) in python with Sentinel2-2A data uisng lzw and deflate with predictor 1 and 2. I tired compressing the image, but I noticed something strange. When I compress a single band the image size reduces to 40%, however as I add more bands the compression rate decreases until I reach 4 bands (B02, B03,B04,B08) where… Read more »